Reflecting on 100M Downloads. The Making of a CLIP model
March 22, 2026
FashionCLIP just reached 100M downloads on HuggingFace. Given the milestone, I wanted to write a bit about how FashionCLIP, and the other CLIP-related work I have done, came to be and how it affected my research career.
This is a story of how small projects that start for fun, can snowball into larger, bigger and more impactful projects.
I fine-tuned 3 CLIPs in the last 6 years and the hard work that was put into each of these has allowed me and many of my colleagues not only to feel proud about our accomplishments, but to also get amazing feedback from the community. This story has multiple characters. It’s a story of colleagues working together but also bonds and friendship. It really takes a village to raise a CLIP model child.
CLIP-Italian
Back in 2021 I was a fresh Postdoc at Bocconi. We were still in COVID-19 times, hopping on public transportation wearing masks and showing vaccination passes to be allowed into buildings. I was already more than one year out of my PhD but somehow the pandemic had reshaped my perception of time and I felt like I had basically just started. Thanks to Dirk Hovy and his amazing lab in Milan, I had lots of freedom to explore any idea I wanted. I was researching different ideas: topic modeling, ethics in AI and general language modeling stuff.1
One day in what I guess was June, HuggingFace announced a new event: the “HuggingFace Community Week”. HuggingFace and Google would provide free TPU access and some tech support to train whatever you wanted - as long as you used JAX to do it. The process was very simple: submit a project proposal on the forum and if approved you are good to go.
While scrolling the various proposals on the forum, I remember seeing a post by someone that wanted to train a language-specific CLIP; I don’t exactly remember what language the OP wanted to train it on but my first thought was to train a CLIP for Italian. I knew little about JAX, I didn’t know a thing about CLIP. I mean I saw the news about CLIP, I just didn’t know what it was in practice. My mental process had been something like “someone is suggesting to do X for language Y let’s do it for Italian”, even if I had little to no idea about how realistic doing X was. Interestingly, the entire code was already provided by the HuggingFace team and they were really active in helping us fix bug and problems; we mostly had to find the data and train.2
I shared my idea with Giuseppe, at the time PhD Student in Turin. Giuseppe and I had chatted and interacted before, but we never had the chance to work together on something. He was very excited about it (we actually recovered the slack message where I asked him about this). After posting on the forum, a few people replied and we had a team of people ready to start grinding for two weeks.
This was our small, fun, low stakes summer project.
However, putting this together in just two weeks was not easy, even with all the code already provided. We had to manage random data download from the web, some messed up image-caption mappings, we were also able to translate only a portion of the 3CC dataset because we didn’t have enough API credits. We had to find data from some remote places and websites. For example we found the very cool WIT dataset that contained Wikipedia images and their respective captions and we extracted the italian subset.3 A fun thing we did was to remove all the captions that contained too many entities because we deemed those not useful in learning good features (e.g., the caption “A dog looking at a red flower” is better than “Justin Bieber in New York City”). We used this arcane and secret NLP technique called POS-Tagging (now it’s illegal to use it) and removed all the captions that were composed of 80% or more proper nouns.
Then we had to choose which encoders to use for the contrastive training, there were a few options for Italian but we had to basically go with vibes because there was no time for ablation studies: Training took a while to run and we only had some TPUs, so we could not scale horizontally.
We were able to put this out there for people to use and we got a surprisingly good reaction. We got some minor news coverage in Italy and we were runners-up for the final awards of the HF community week. CLIP Italian also had a cameo on Yannic Kilcher video newsletter!
We didn’t know what to do with CLIP-Italian, we wrote an arxiv paper and it was kept only on arxiv for two years. Then we decided to submit this to the Italian NLP conference and gave this work a little house. To our surprise we won the best student paper award.
The model we got out of the project was actually pretty good! It might be hard to believe in 2026, but back in 2021 the fact that a simple multi-modal model could retrieve “two dogs on the snow” in Italian was out of the ordinary. Those were the first hints of semantic understanding in embedding models.4
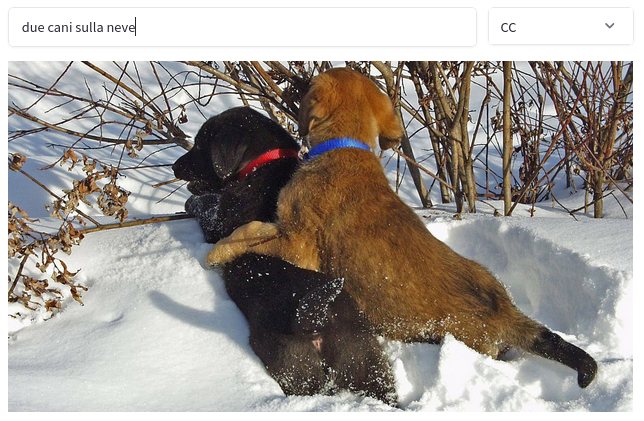
Why am I telling you about CLIP-Italian? because that was the stepping stone for FashionCLIP.
FashionCLIP
I had been collaborating with Jacopo on various projects related to the ecommerce sector for a few years at this point.
After he saw CLIP-Italian, he asked if it would be possible to train a similar model but for the e-commerce and it was actually a great idea. Spoiler: this is another example of a fun project where we just wanted to see what the model could do.
Jacopo got in contact with Diogo at Farfetch and Diogo found a way to give us access to some of that data that Farfetch was using. To this day, that data is one of the cleanest datasets I have ever seen. Amazing annotation quality, well written captions, labels for all the properties you could imagine.
Jacopo then introduced me to Patrick, who at the time was his employee and is now a close friend of mine. I rewrote the training of CLIP from JAX to Pytorch and then Patrick ported the entire thing to Metaflow so we could even spend even more money than what we were already spending by just deploying this on AWS machines with one CLI command. Patrick made CLIP run on multiple GPUs so that we could scale the batch size which also improved the performance. We trained this model and it was surprisingly good.
Publishing FashionCLIP was not easy: we submitted to the 2022 NAACL Industry Track but the paper was sadly rejected. Maybe it was not the perfect fit but that was a real bummer.5 I think we were discouraged for a little while; it’s hard to find a place for a new model as the contribution is partially limited. However, we did not give up. Eventually, we just decided to submit FashionCLIP to Scientific Reports. Scientific Reports tends to accept anything that is well made forgetting about the novelty factor, so we thought it could be a good venue to close this chapter of our life. After a few months of reviewing, the paper was finally accepted in November 2022.
We were happy with this conclusion. However, we didn’t expect FashionCLIP to be used as much. 100M downloads is a huge number. FashionCLIP is and has been used in Fortune 500 companies and many startups. I met random people in random places and they were excited when I told them I worked on FashionCLIP because they were using it in production. There is a big difference between what goes in academia and what is actually useful in Industry. FashionCLIP was definitely the second.
This is the type of contributions that reviewers tend to hate because they are not really innovative in the general sense. There is obvious tension between publishing something useful and something that is groundbreakingly innovative. This was a scientific-engineering contribution, but the scientific part of it was appreciated less than the artifact we produced.
The question is, was this industry contribution useful to my career? Yes, absolutely. I attribute it as part of the reason I was able to land other academic positions. Showing you can produce relevant artifacts is still very important, even if academia does not reward this knowledge in the short term, it can be very worth it in the long run.
I attribute this success to two things: a very permissive licensing and the fully open-source release (easy to use code and easy to download model, with an API compatible with OpenAI’s one): this made the model a drop in replacement for any Fashion pipeline that was using CLIP.
As of March 16th 2026, FashionCLIP is still the second most trending model on the platform.6
PLIP
This story ends with PLIP, a CLIP model for pathology.
I arrived at Stanford in 2022 after my first two CLIPs were out and I gave a talk on my research to James Zou’s lab during one of the hot days of summer. I remember that it was very hot because in my first few days on campus the power went out for 2 or 3 days. The first few days, I was staying at a hotel far from campus and I had to walk 1h every day to get to campus (and one hour back).
James had introduced me to his then first-year PhD student Mert who was around during those days of summer, and we started working together. That was the start of one of the most enjoyable and fruitful collaborations I have ever had the pleasure to have. Mert and I were digging into why CLIP-like models often failed compositionally and found very cool failures in these models.
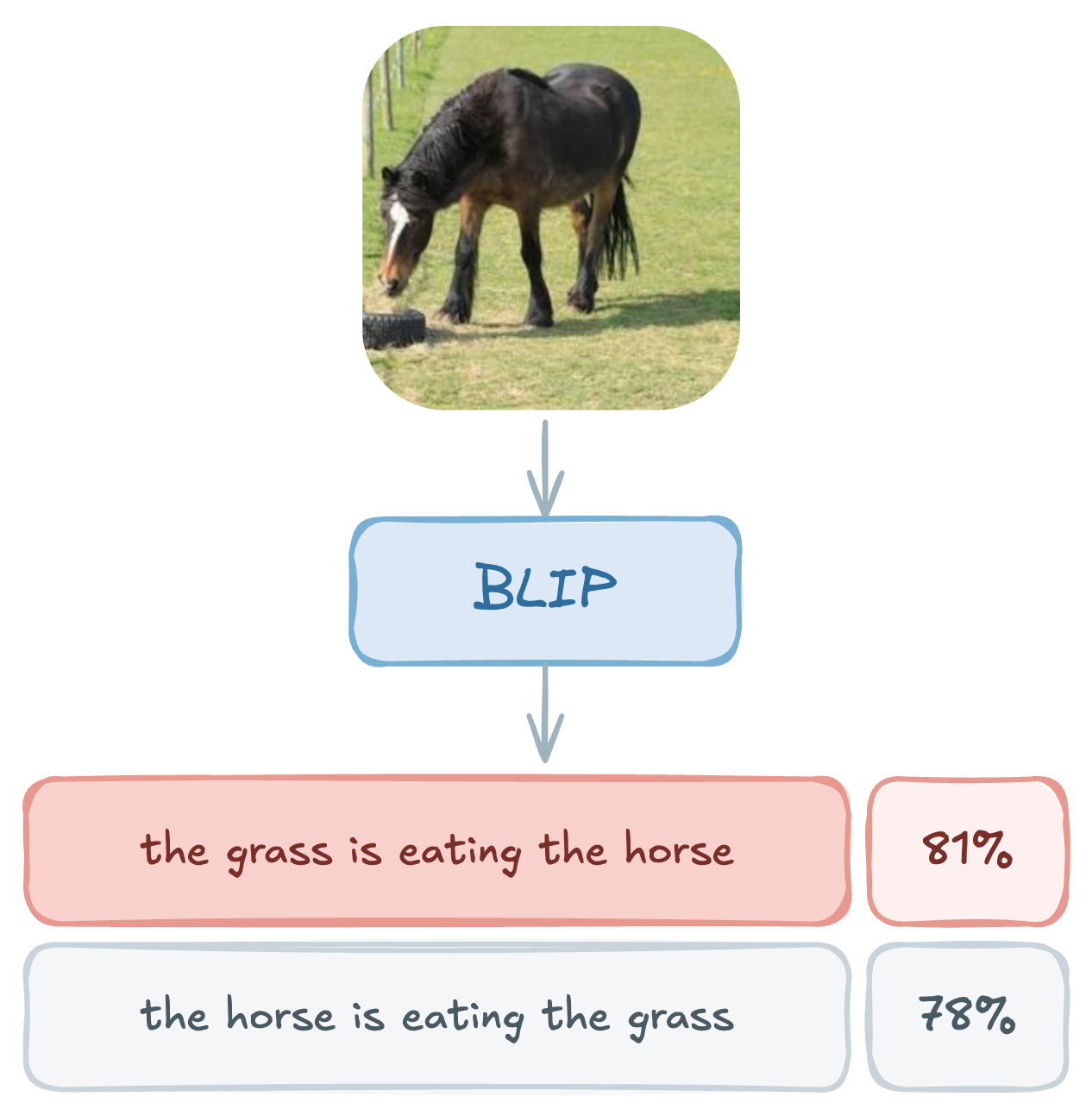
We went on analyzing vision-language models and published an ICLR 2023 paper that was accepted for an Oral presentation.
A few weeks after that paper came out, Zhi Huang, a postdoc with James at that time and now is a very cool Professor at UPenn, reached out to me: he had been collecting some Twitter data with image-text pairs that could be used to train a CLIP model. The data was very cool: it was a collection of 270k tweets from what we could refer to as “Pathology Twitter”, full of doctor posting cases and discussing different aspects of rare pathology slides. Pathology Twitter is a fascinating aspect of modern digital medicine: the possibility of sharing and asking for help online, the discussions on rare cases, the interactions of a community of highly specialized experts. Indeed, the College of American Pathologist for example, invites pathologists to grow a digital presence. We both thought that this data was definitely useful as a proxy to learn good representations of text and images for a very specific medical domain.
So Zhi, our partner in crime Mert, and I started working on this project. In a few weeks we had our first prototype. This work was also not without its own set of hurdles to overcome. I mainly focused on fine-tuning the CLIP model for pathology and some additional data collection. On the other hand, Zhi and Mert had to do a lot of data cleaning: Twitter data is never pristine. They had to develop custom classifiers to clean the data. We needed also some non-Twitter data, to ensure that those representations were actually well distributed and structured. Thus, I helped collecting additional pathology images by sampling pathology data from the famous LAION dataset; the LAION API allowed you to submit an image and retrieve the link to the top N similar images in the dataset: doing this a bunch of times and then applying the classifier is enough to get a good set of images you can train on. The model itself was not perfect, but it was actually pretty good! We performed well in both retrieval and probing tasks (i.e., treating our tuned vision encoder as a feature generation), which made for a useful model for the community.
The final output of our hard work was a paper that found home at Nature Medicine, with a process that was surprisingly much smoother than the previous CLIPs: we submitted and we got the first round of reviews in a reasonable amount of time. Reviewers asked for quite a bit of ablations but it ended up being mostly about taking the time to run additional experiments to convince them, no major reshaping of the paper was required.
PLIP is another example of things done for fun with colleagues that then became friends. To this day, PLIP is my most cited paper, getting closer to 1000 citations and as of March 16th 2026, PLIP is the 10th most trending model on the platform, with a total of 5M downloads.
There is not much more to say if not that I am grateful that I have been able to work with such amazing folks. Who knows where I would be if that summer I didn’t scroll the forum and opened the post that gave me the idea to train a CLIP in Italian. I was there on my laptop, unprepared and not knowing what I was doing, but I initiated the project anyway. A small, fun, summer project opened doors to new collaborations, opportunities and friendships that have lasted.
-
By the way, this was back when encoder-only models were the best thing ever. ↩
-
Note: it was not really like the original CLIP but just two encoders, one based on BERT and the other was a ViT something something. ↩
-
Yes, this dataset now has 400 citations, but it did not have 400 citations back in 2021 so it was definitely a lucky find! I just checked and it got 19 citations in 2021. ↩
-
Yes of course I remember Word2Vec and sentence embeddings methods, but multi-modal retrieval gives completely different vibes. ↩
-
The year before we won the best paper award at the same track. ↩
-
Fun fact about FashionCLIP: due to resizing and cropping, if you are not careful, most pants will be predicted as shorts. If the model crops the bottom of the pants they look like shorts. Always resize images correctly. ↩