Abstract
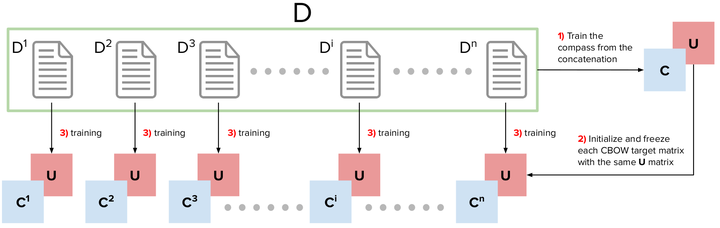
Temporal word embeddings have been proposed to support the analysis of word meaning shifts during time and to study the evolution of languages. Different approaches have been proposed to generate vector representations of words that embed their meaning during a specific time interval. However, the training process used in these approaches is complex, may be inefficient or it may require large text corpora. As a consequence, these approaches may be difficult to apply in resource-scarce domains or by scientists with limited in-depth knowledge of embedding models. In this paper, we propose a new heuristic to train temporal word embeddings based on the Word2vec model. The heuristic consists in using atemporal vectors as a reference, i.e., as a compass, when training the representations specific to a given time interval. The use of the compass simplifies the training process and makes it more efficient. Experiments conducted using state-of-the-art datasets and methodologies suggest that our approach outperforms or equals comparable approaches while being more robust in terms of the required corpus size.
Federico Bianchi
Postdoctoral Researcher at Stanford University
My research interests include developing and understanding large language (and vision) models and recommender systems.