On Pushing The Boundaries of Mathematics
March 15, 2026
I was never a smart kid and I probably never will be. I hated going to school and math class was, unfortunately, part of the curriculum. I distinctly remember the painful stomach ache I used to get on test day. While the day before I was procrastinating by playing video games and, of course, not studying, the day of the test was filled with angst and anxiety waiting for the teacher to get to class and hand me the test sheet. Even just recalling some of those moments makes me feel a little uncomfortable.
However, it seems like destiny offered me the chance to go back to the math domain and provide my marginal contribution to its development.
As a matter of fact, these days, I am finding myself more and more in the field of what you would call “just throw compute at the problem and it is probably going to solve itself”. Due to the well-definedness of open math problems, these are the first type of problems we tend to tackle.
Many math problems have a very nice shape: they are easy to evaluate and there is no way you are going to clown yourself by releasing something that is incorrect. If the verifier tells you that you have a better score than past state of the art scores then you are done — you have a new result that can go on Wikipedia.1
construction = fancy_llm()
verify(construction)
Moreover, some of these problems ask you to look for new lower or upper bounds, so you can train a model and hill-climb on the verification itself (this is what we have done in TTT-Discover). Researchers really like these problems for these exact features.
We recently discovered a few bounds for new mathematical problems and it was quite a huge hit.2 TTT-Discover was our first attempt at test time training for scientific discovery.
I do not understand these problems — I don’t have the mathematical knowledge required. To be clear, I probably could understand them if I spent a few hours working on them, but I don’t need to. AI allows me to push the boundaries of these problems without knowing the structure of the problem itself.
Even more recently, we found a new bound for one of the Erdős’ problems. The new upper bound was obtained by letting a few agents chat on social media and submit solutions to problems.
I do believe this is both good and bad. It’s good because I can help science going forward, it’s bad because, technically, I don’t know what I am doing. While these problems are, at the best of my knowledge, pretty harmless, the fact that I don’t need to understand what I am working on to push the boundaries is kind of problematic.
Erdős’ Minimum Overlap Problem
Here is the definition of the problem, as stated in online resources.
The problem, posed by Paul Erdős in 1955, asks: if you partition the numbers \(1, 2, \ldots, 2n\) into two sets \(A\) and \(B\) of equal size, how much must they overlap when shifted? More formally, how large must \(\max_k \vert A \cap (B + k) \vert\) be?
This translates into finding a constant \(C\) that bounds the overlap. The current known bounds are:
\[0.379005 \leq C \leq 0.380871\]The lower bound comes from convex programming,3 and we just pushed the upper bound lower using AI-driven sequential linear programming.
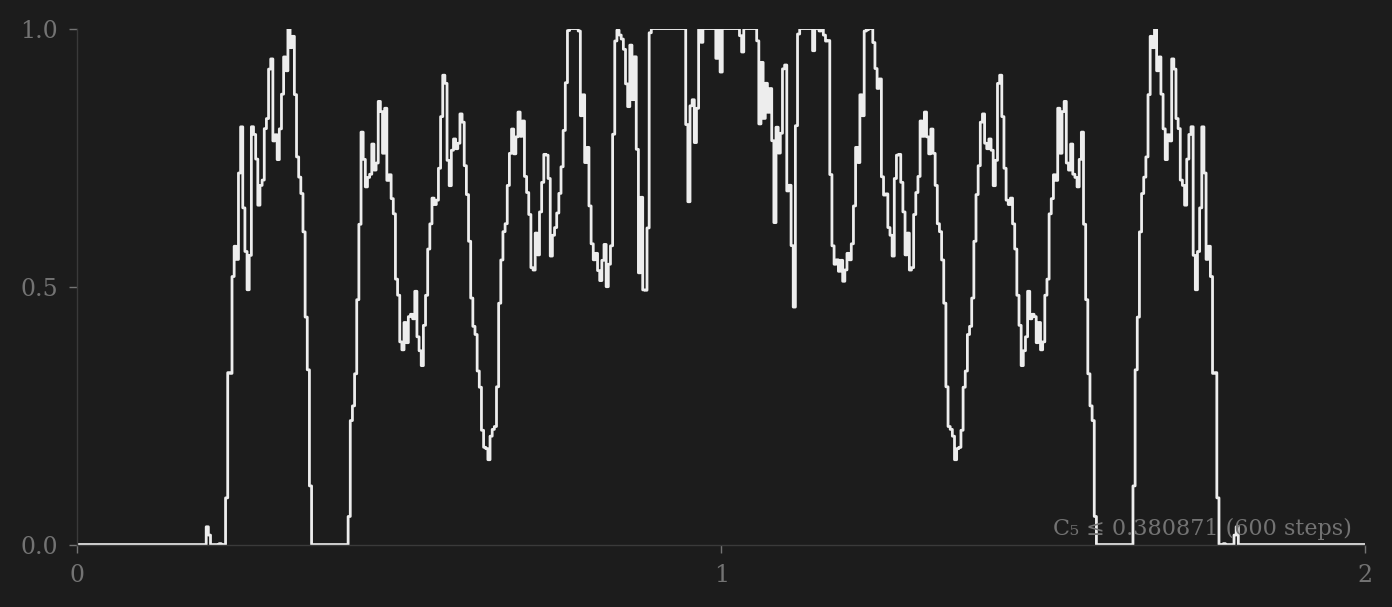
The step function above achieves the new state-of-the-art upper bound of \(C \leq 0.380871\) with 600 steps, improving on the previous best of 0.380876.